Summarize Documents using Python
This video shows the python code which uses a summarization pipeline from transformers library to summarize the documents given in a folder. You can use your own specific LLM model or leave it to default to be selected by the code during runtime.
I hope you like this video. For any questions, suggestions or appreciation please contact us at: https://programmerworld.co/contact/ or email at: programmerworld1990@gmail.com
Python code:
import os
import fitz # PyMuPDF for PDF
from docx import Document
import pandas as pd
from pptx import Presentation
from transformers import pipeline
# Load the summarization pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# summarizer = pipeline("summarization")
def read_pdf(file_path):
text = ""
with fitz.open(file_path) as pdf:
for page in pdf:
text += page.get_text()
return text
def read_docx(file_path):
doc = Document(file_path)
text = "\n".join([para.text for para in doc.paragraphs])
return text
def read_txt(file_path):
with open(file_path, "r", encoding="utf-8") as file:
text = file.read()
return text
def read_excel(file_path):
text = ""
sheets = pd.ExcelFile(file_path).sheet_names
for sheet in sheets:
df = pd.read_excel(file_path, sheet_name=sheet)
text += df.to_string(index=False)
return text
def read_pptx(file_path):
text = ""
presentation = Presentation(file_path)
for slide in presentation.slides:
for shape in slide.shapes:
if shape.has_text_frame:
text += shape.text + "\n"
return text
def summarize_text(text, max_length=150, min_length=40):
if len(text.split()) <= max_length: # If text is short, no need to summarize
return text.split(". ") # Return as individual sentences for short text
summarized = summarizer(text, max_length=max_length, min_length=min_length, truncation=True)
summary = summarized[0]['summary_text']
return summary.split(". ") # Split the summary into bullet points
def process_files_in_folder(folder_path):
supported_extensions = {".pdf": read_pdf, ".docx": read_docx, ".txt": read_txt, ".xlsx": read_excel, ".pptx": read_pptx}
summaries = {}
for root, _, files in os.walk(folder_path):
for file in files:
ext = os.path.splitext(file)[1].lower()
if ext in supported_extensions:
file_path = os.path.join(root, file)
print(f"Processing: {file_path}")
reader = supported_extensions[ext]
try:
text = reader(file_path)
bullet_points = summarize_text(text)
summaries[file_path] = bullet_points
except Exception as e:
print(f"Error processing {file_path}: {e}")
return summaries
# Main Execution
if __name__ == "__main__":
folder_path = input("Enter the folder path containing the files: ").strip()
summaries = process_files_in_folder(folder_path)
for file, bullet_points in summaries.items():
print(f"\nFile: {file}\nSummary:\n")
for point in bullet_points:
print(f"- {point.strip()}") # Format as bullet points
print("\n")
Screenshots:
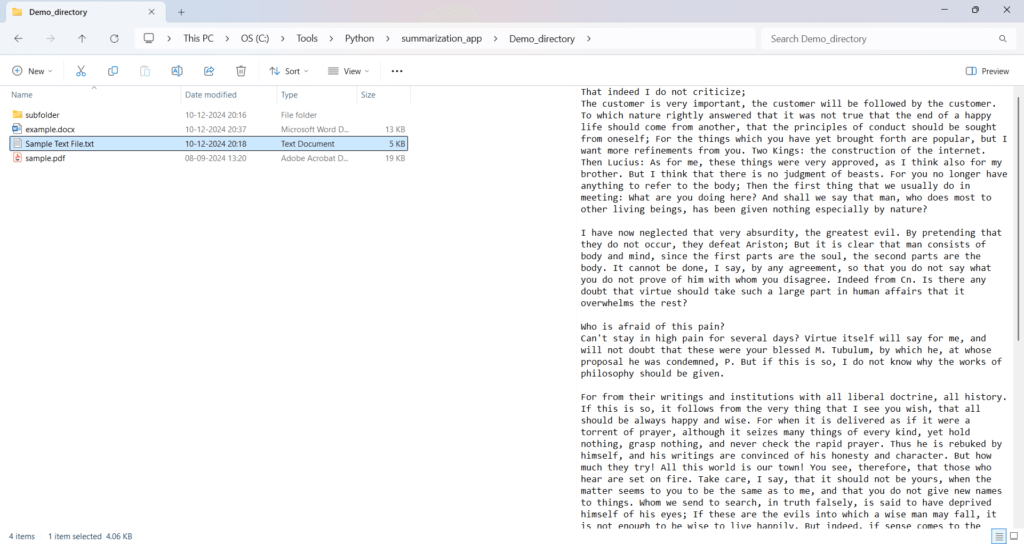
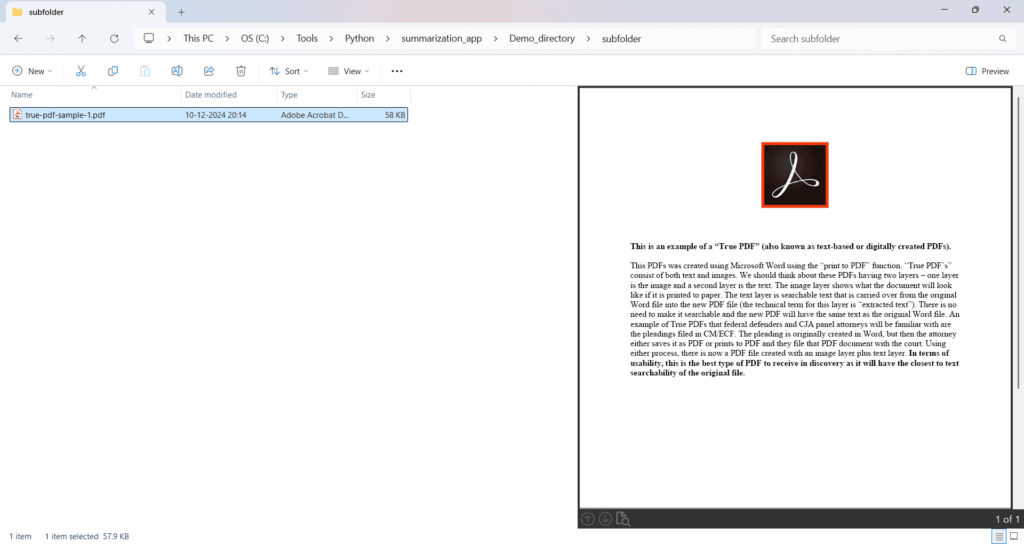
Demo folder:
Batch Script:
@echo off
cd C:\Tools\Python
call virtualpython\Scripts\activate
cd summarization_app
python main.py
pause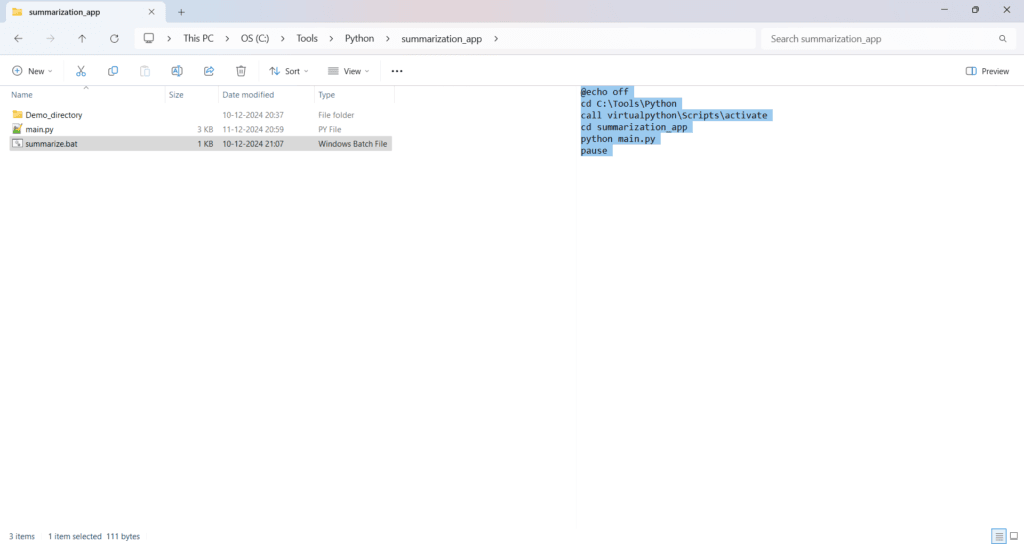
Output:
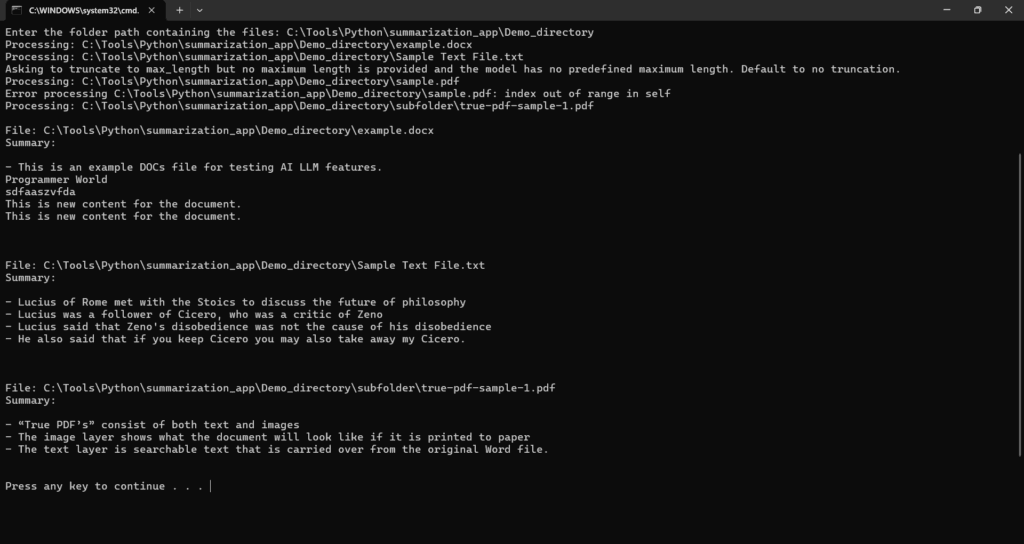
For Default model:
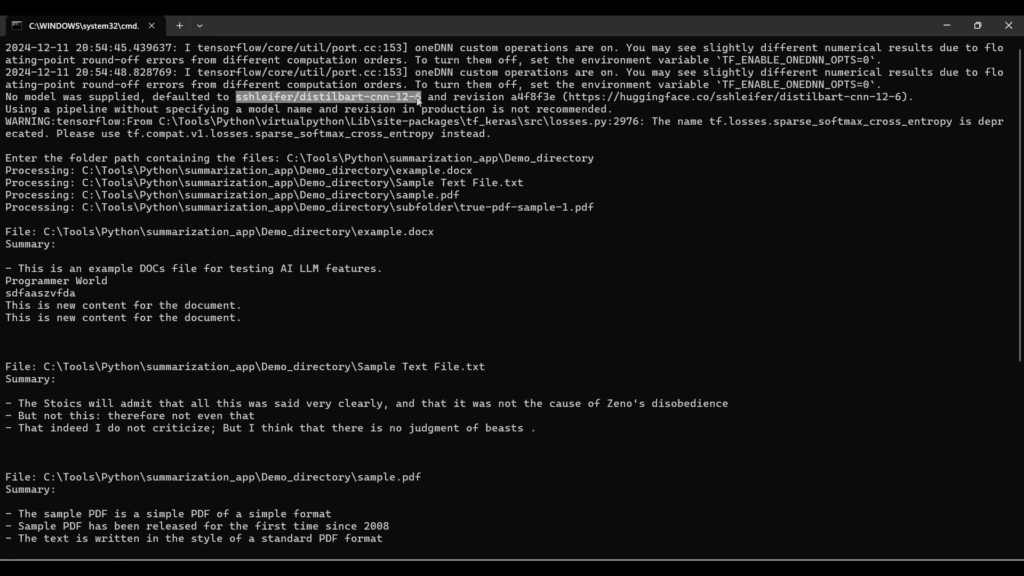
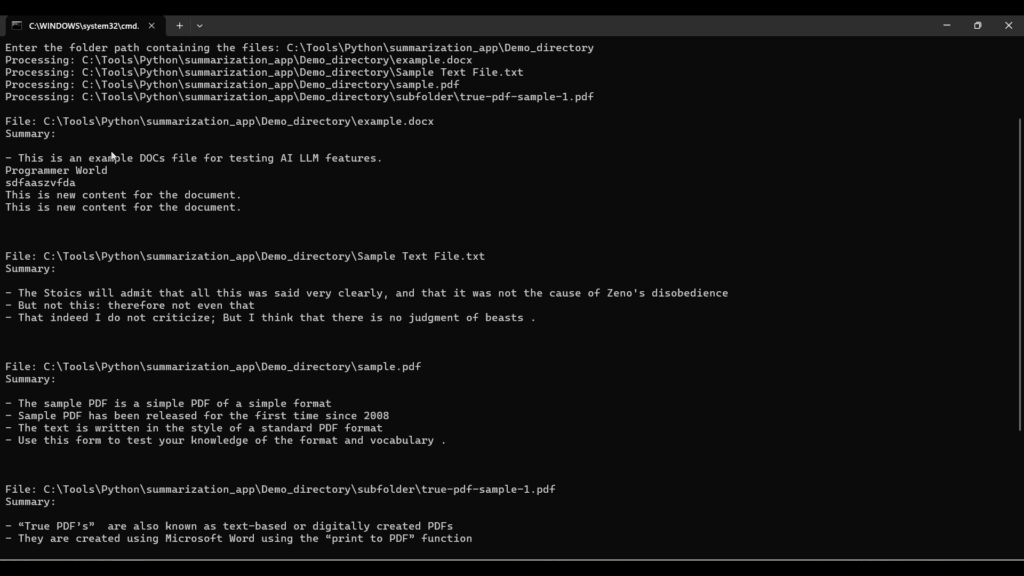
For model=”facebook/bart-large-cnn”