
Search all the documents in windows OS
In this video it shows the demo of how to search all the documents in a windows folder (including subfolders) for a particular query string. In this demonstration, the app is developed using the Python code.
I hope you like this video. For any questions, suggestions or appreciation please contact us at: https://programmerworld.co/contact/ or email at: programmerworld1990@gmail.com
Details:
Python code:
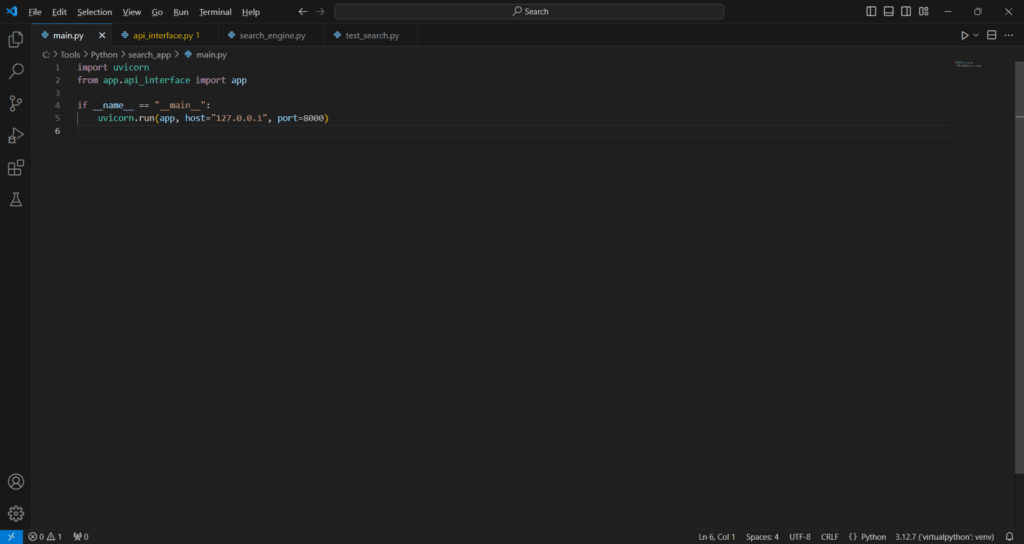
.\search_app\main.py
import uvicorn
from app.api_interface import app
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000)
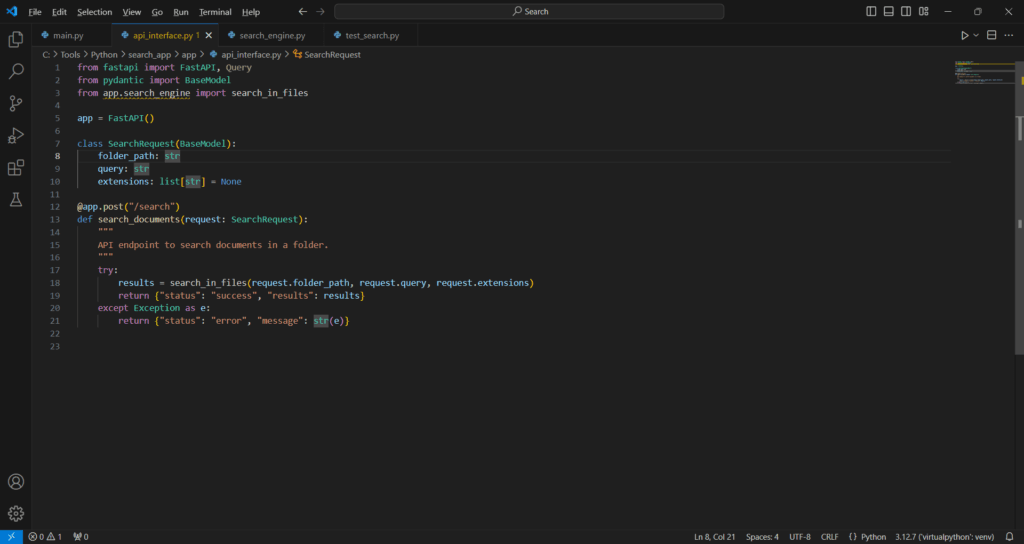
.\search_app\app\api_interface.py
from fastapi import FastAPI, Query
from pydantic import BaseModel
from app.search_engine import search_in_files
app = FastAPI()
class SearchRequest(BaseModel):
folder_path: str
query: str
extensions: list[str] = None
@app.post("/search")
def search_documents(request: SearchRequest):
"""
API endpoint to search documents in a folder.
"""
try:
results = search_in_files(request.folder_path, request.query, request.extensions)
return {"status": "success", "results": results}
except Exception as e:
return {"status": "error", "message": str(e)}
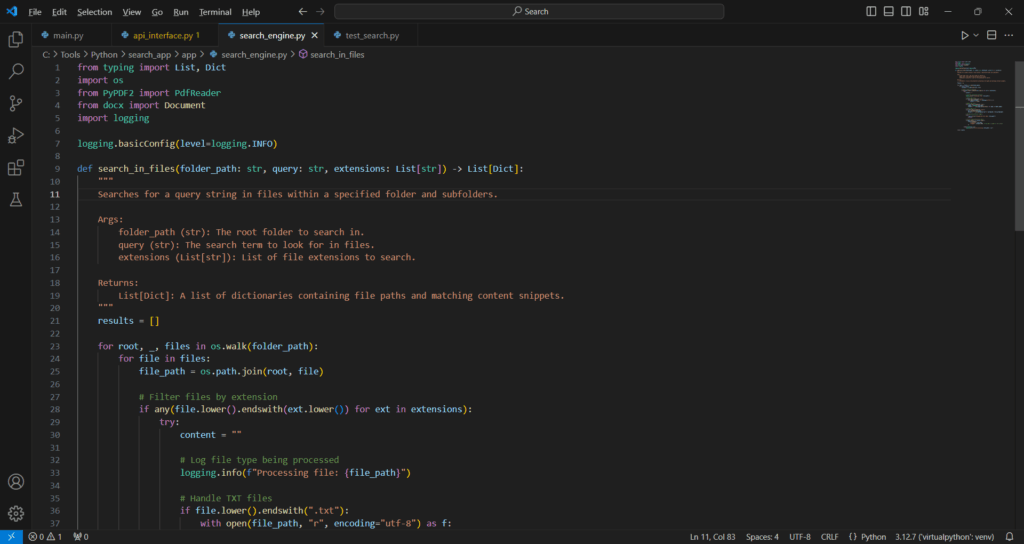
.\search_app\app\search_engine.py
from typing import List, Dict
import os
from PyPDF2 import PdfReader
from docx import Document
import logging
logging.basicConfig(level=logging.INFO)
def search_in_files(folder_path: str, query: str, extensions: List[str]) -> List[Dict]:
"""
Searches for a query string in files within a specified folder and subfolders.
Args:
folder_path (str): The root folder to search in.
query (str): The search term to look for in files.
extensions (List[str]): List of file extensions to search.
Returns:
List[Dict]: A list of dictionaries containing file paths and matching content snippets.
"""
results = []
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
# Filter files by extension
if any(file.lower().endswith(ext.lower()) for ext in extensions):
try:
content = ""
# Log file type being processed
logging.info(f"Processing file: {file_path}")
# Handle TXT files
if file.lower().endswith(".txt"):
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
# Handle PDF files
elif file.lower().endswith(".pdf"):
reader = PdfReader(file_path)
content = " ".join(page.extract_text() for page in reader.pages)
# Handle DOCX files
elif file.lower().endswith(".docx"):
doc = Document(file_path)
content = " ".join(paragraph.text for paragraph in doc.paragraphs)
# Unsupported extension logging
else:
logging.error(f"Unsupported file type: {file_path}")
continue
# Perform case-insensitive search
if query.lower() in content.lower():
results.append({
"file_path": file_path,
"snippet": content[:200], # Include a snippet of the content
})
except Exception as e:
logging.error(f"Error processing {file_path}: {e}")
return results
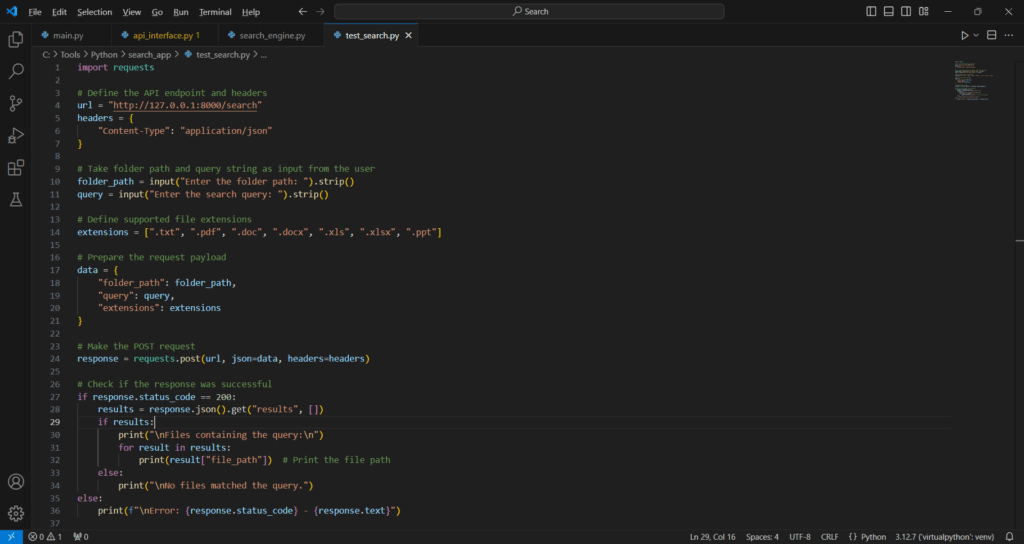
.\search_app\test_search.py
import requests
# Define the API endpoint and headers
url = "http://127.0.0.1:8000/search"
headers = {
"Content-Type": "application/json"
}
# Take folder path and query string as input from the user
folder_path = input("Enter the folder path: ").strip()
query = input("Enter the search query: ").strip()
# Define supported file extensions
extensions = [".txt", ".pdf", ".doc", ".docx", ".xls", ".xlsx", ".ppt"]
# Prepare the request payload
data = {
"folder_path": folder_path,
"query": query,
"extensions": extensions
}
# Make the POST request
response = requests.post(url, json=data, headers=headers)
# Check if the response was successful
if response.status_code == 200:
results = response.json().get("results", [])
if results:
print("\nFiles containing the query:\n")
for result in results:
print(result["file_path"]) # Print the file path
else:
print("\nNo files matched the query.")
else:
print(f"\nError: {response.status_code} - {response.text}")
Screenshots:
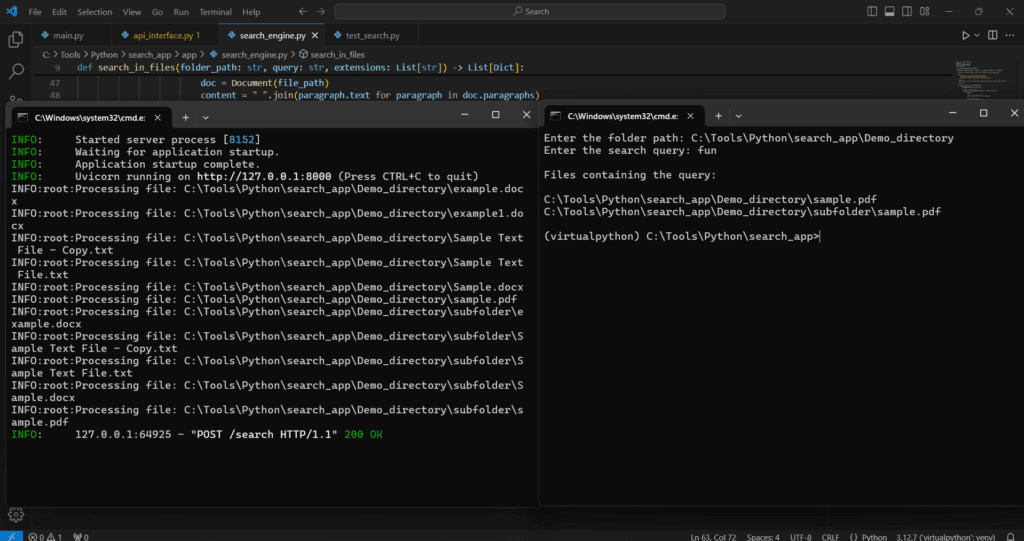
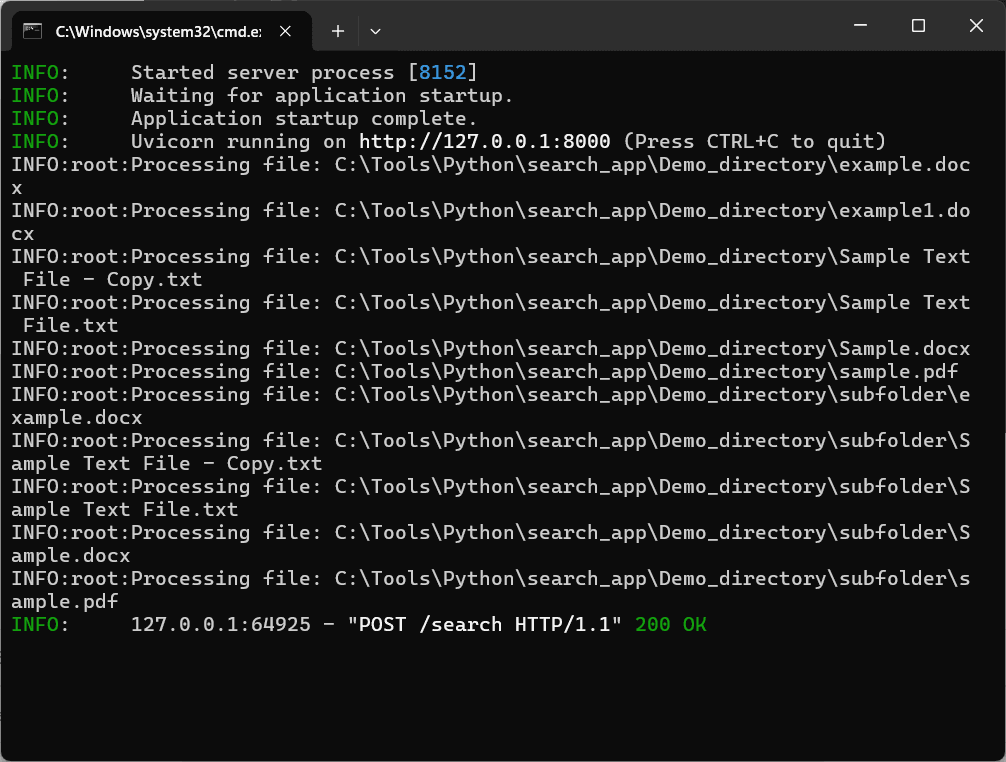
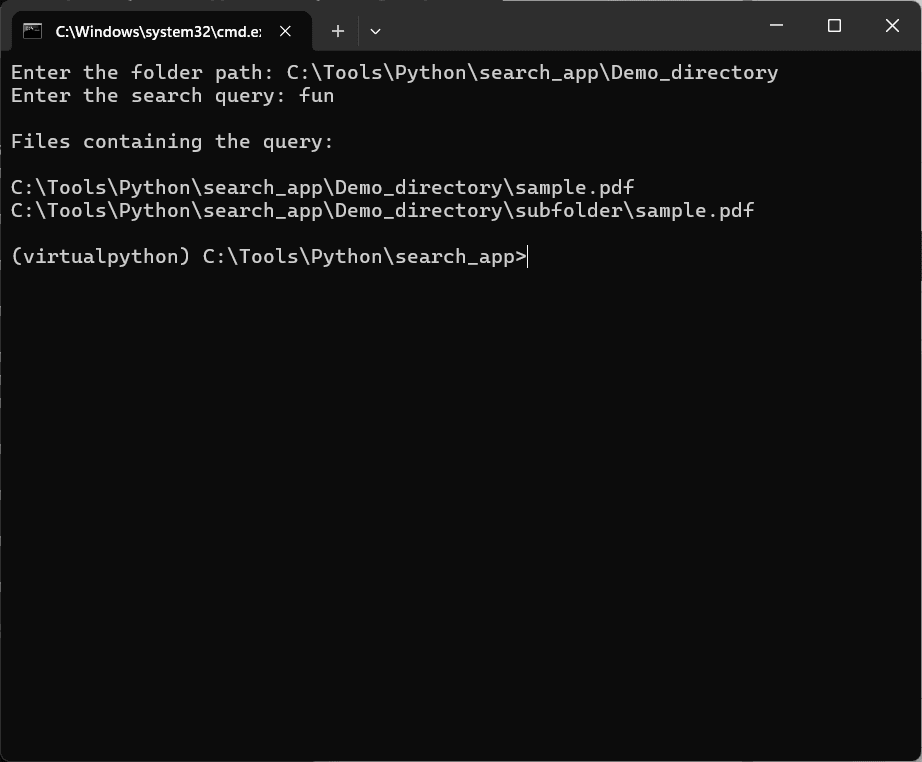
The complete python code of the App along with the batch script is shared in the below link:
https://drive.google.com/file/d/1pck47f3URlwe857jdVtElVyxe5umXKjr/view?usp=sharing